有很多人咨詢過(guò)筆者(Mr.Zhao),百度如何判斷偽原創(chuàng)和原創(chuàng)?百度喜歡什么樣的文章?什么樣的文章比較例如獲得長(zhǎng)尾詞排名?等等諸如此類的問題。面對(duì)這些問題,我常常不知如何回答。如果我給一個(gè)比較大方向一些的答案,例如要重視用戶體驗(yàn)、要有意義等等,那么提問者會(huì)覺得我在應(yīng)付他,他們往往抱怨說(shuō)這些太模糊。可是我也沒法再給出具體的內(nèi)容,畢竟我不是百度,具體算法我又何德何能的為你們指點(diǎn)江山呢?
為此,我開始寫這個(gè)“如果是我”系列的文章。在這一系列文章里,我假設(shè)如果是我絞盡腦汁的來(lái)為網(wǎng)民提供較好的搜索服務(wù),我會(huì)怎么做,我會(huì)怎么對(duì)待文章內(nèi)容、如何對(duì)待外鏈、如何對(duì)待網(wǎng)站結(jié)構(gòu)等等諸如此類的站點(diǎn)元素。當(dāng)然,本人技術(shù)有限,我只能寫一點(diǎn)我稍微理解的東西。而百度以及其它的商業(yè)搜索引擎,他們有大量比我優(yōu)秀的人才,相信他們的算法以及處理問題的方式會(huì)比我完善很多,而我之所以寫這些,無(wú)外乎拋磚引玉,希望大家看后,心里有一個(gè)大概。畢竟在SEO的道路上走過(guò)一段時(shí)間后,沒有誰(shuí)能夠當(dāng)誰(shuí)的老師,一些觀點(diǎn)僅供參考。
************重要的聲明*******************************
在此,我要鄭重聲明,這個(gè)系列文章中所有涉及到的思想、算法與程序,均非本人所寫,全部是我從一些公開的資料里搜集而得的。同時(shí),相信大家也能理解,如果這些免費(fèi)公開的東西都能做到如此程度,那么那些商業(yè)機(jī)密就更不用提了。
******************************************************
好的,現(xiàn)在開始。
如果是我,我會(huì)喜歡什么樣子的文章呢?我會(huì)喜歡我的用戶喜歡的文章,如果硬要加判定標(biāo)準(zhǔn),那無(wú)外乎是兩種:1.原創(chuàng)且用戶喜歡。2.非原創(chuàng)且用戶喜歡。在這里,我的態(tài)度很明顯,偽原創(chuàng)就是非原創(chuàng)。那么用戶喜歡什么樣的文章呢?很顯然,一些新觀點(diǎn)、新知識(shí)往往是用戶喜歡的,也就是說(shuō)通常原創(chuàng)文章都是用戶喜歡的,而且即便用戶不喜歡,原創(chuàng)站點(diǎn)作為新鮮內(nèi)容的制造者,也應(yīng)該受到一定的保護(hù)。那么非原創(chuàng)的文章用戶就一定不喜歡嗎?誠(chéng)然否也。一些站點(diǎn),其內(nèi)容往往是經(jīng)過(guò)搜集整理后聚合而成的,那么這些站點(diǎn)對(duì)用戶來(lái)說(shuō)就是有價(jià)值的,其相對(duì)應(yīng)的文章理應(yīng)獲得較好的排名。
由此可見,我需要重視兩類文章即可。一是原創(chuàng)文章,二是有價(jià)值的信息聚合站點(diǎn)下的文章。
首先要明確一點(diǎn),本文探討范圍僅限內(nèi)容頁(yè),而非專題頁(yè)、列表頁(yè)和首頁(yè)。
那么我在甄別這兩類文章之前,我需要先進(jìn)行信息的采集。本文對(duì)于spider程序部分不進(jìn)行闡述。當(dāng)spider程序下載下來(lái)網(wǎng)頁(yè)信息后,在內(nèi)容處理的模塊中,我需要先對(duì)內(nèi)容除噪。
內(nèi)容除噪,并非大家經(jīng)常性的誤以為僅僅除去代碼而已。對(duì)于我來(lái)說(shuō),我還要出去頁(yè)面部分非正文內(nèi)容的文字。比如導(dǎo)航條、比如底部文字以及各個(gè)文章列表。將它們的影響除去后,我將得到一段僅僅包含網(wǎng)頁(yè)正文內(nèi)容的文本段落。寫過(guò)采集規(guī)則站長(zhǎng)朋友應(yīng)該知道,這個(gè)并不難。但搜索引擎畢竟是一款程序,不可能針對(duì)每個(gè)站寫個(gè)類似于的采集規(guī)則的東西,所以我需要建立一套除噪算法。
在此之前,我們先明確我們的目的。
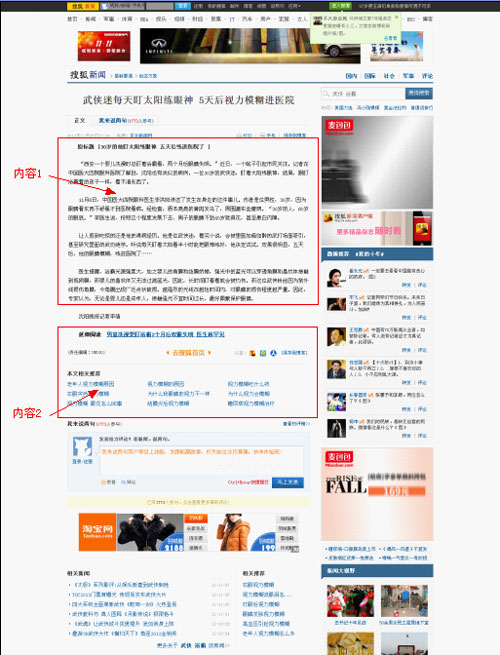 ?
?
上圖中很明顯內(nèi)容1是用戶最為需要的,內(nèi)容2是用戶可能感興趣的,其余均是無(wú)效的噪音。那么針對(duì)于此,我們可以發(fā)現(xiàn)如下幾特征:
1.所有的調(diào)用列表全部是在一個(gè)信息塊里,這個(gè)信息塊絕大部分是由標(biāo)簽組成,即便有游離于標(biāo)簽的內(nèi)容,其文字也基本是固定的,且在站內(nèi)頁(yè)面中存在大量重復(fù),較為容易判斷。
2.內(nèi)容2一般緊鄰著內(nèi)容1。而且內(nèi)容2中的鏈接錨文本,與內(nèi)容1存在相關(guān)性。
3.內(nèi)容1部分,是有文字文本內(nèi)容和標(biāo)簽混合而成,且在通常情況下,文本文字內(nèi)容在網(wǎng)站網(wǎng)頁(yè)集合中具有唯一性。
那么,針對(duì)于此,我采用廣為人知的標(biāo)簽樹方式,將內(nèi)容頁(yè)進(jìn)行分解。
從網(wǎng)頁(yè)的標(biāo)簽布局上來(lái)看,網(wǎng)頁(yè)是通過(guò)若干的信息塊來(lái)提供內(nèi)容的,而這些信息塊又是由特定的標(biāo)簽規(guī)劃出來(lái)的,常見的標(biāo)簽有<div><ul><li><p><table><tr><td>等,我們依照這些標(biāo)簽,將網(wǎng)頁(yè)費(fèi)解為樹狀結(jié)構(gòu)。
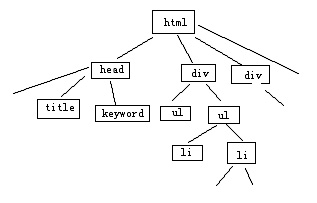
上圖是我手繪的簡(jiǎn)單的標(biāo)簽樹,通過(guò)這種方式,我可以非常輕松的識(shí)別出各個(gè)信息塊。然后我設(shè)定一定闕值A(chǔ)為內(nèi)容比重闕值。內(nèi)容比重闕值為信息塊中文本字?jǐn)?shù)與標(biāo)簽出現(xiàn)此處的比值。我設(shè)定當(dāng)網(wǎng)頁(yè)中信息塊內(nèi)容比重闕值大于A時(shí),才會(huì)被我列為有效內(nèi)容塊(此舉是為了杜絕過(guò)分的多內(nèi)鏈,因?yàn)槿绻黄恼虏紳M內(nèi)鏈,則不利于用戶體驗(yàn)),然后我再比對(duì)內(nèi)容塊中的文本,當(dāng)其具有唯一性時(shí),此一個(gè)或多個(gè)內(nèi)容塊的集合,即為我所需要的“內(nèi)容1”。
那么內(nèi)容2我要如何處理呢?在講解處理內(nèi)容2之前,我先講解一下內(nèi)容2的意義。正如我先前所說(shuō),如果是一個(gè)注重用戶體驗(yàn)的聚合性網(wǎng)站,那么他的作用是將現(xiàn)有的互聯(lián)網(wǎng)內(nèi)容經(jīng)過(guò)精心的分類與關(guān)聯(lián),來(lái)方便用戶更好、更有效的閱讀。針對(duì)這樣的站點(diǎn),即便其文章不是原創(chuàng)而是從互聯(lián)網(wǎng)上摘抄的,我也會(huì)給予其足夠的重視與排名,因?yàn)樗己玫木酆蟽?nèi)容往往更能滿足用戶的需求。
那么針對(duì)聚合站點(diǎn),我可以通過(guò)“內(nèi)容2”來(lái)進(jìn)行粗略的判斷。簡(jiǎn)而言之,如果是一個(gè)良好的聚合站點(diǎn),首先其內(nèi)容頁(yè)必須存在內(nèi)容2,同時(shí)內(nèi)容2必須占重要部分。
好了,識(shí)別內(nèi)容2很簡(jiǎn)單,對(duì)于內(nèi)容比重闕值低于某個(gè)特定值的信息塊,我全部判斷為鏈接模塊。我將內(nèi)容1通過(guò)某些方式(具體方式本文后半部分講解),提取出主題B。我將鏈接模塊中的所有標(biāo)簽的錨文本分別進(jìn)行分詞,如果所有的錨文本均與主題B相符,則將此鏈接模塊判定為內(nèi)容2。設(shè)定鏈接闕值C,鏈接闕值為內(nèi)容2中標(biāo)簽出現(xiàn)次數(shù)除以所有鏈接模塊所出現(xiàn)的標(biāo)簽次數(shù)所得的比重,若大于C,則此網(wǎng)站可能為聚合網(wǎng)站,針對(duì)內(nèi)容排名計(jì)算時(shí)會(huì)引用聚合站點(diǎn)特定的算法。
******************拓展閱讀1開始***************************************
我相信很多SEO從業(yè)者剛接觸這行時(shí),就聽說(shuō)過(guò)一件事,就是內(nèi)容頁(yè)面導(dǎo)出鏈接要具有相關(guān)性。還有一件事,就是頁(yè)面下面要有相關(guān)閱讀,來(lái)吸引用戶縱深點(diǎn)擊。同時(shí)應(yīng)該還聽人講過(guò),內(nèi)鏈要適中,不可太多等。
但很少有人會(huì)說(shuō)為什么,而越來(lái)越多的人因?yàn)椴幻髌鋬?nèi)在道理,而漸漸忽視了這些細(xì)節(jié)。當(dāng)然,以前的一些搜索引擎算法在內(nèi)容上的注重程度不夠,也起到了推波助瀾的作用。但是,如果從陰謀論的角度上來(lái)看,我可以假設(shè)出這么一個(gè)道理。
絕大部分用戶的搜索頁(yè)面,第一頁(yè)只有10個(gè)結(jié)果,除去我自家產(chǎn)品,往往僅剩下7個(gè)左右,一般用戶最多只會(huì)點(diǎn)擊到第3頁(yè),那么我需要的優(yōu)質(zhì)站點(diǎn)其實(shí)不到30個(gè)就可以最大限度的滿足用戶體驗(yàn)。那么經(jīng)過(guò)3-5年的布局,逐漸篩選出一些耐得住寂寞和認(rèn)真做細(xì)節(jié)的站,這時(shí)候我再將這一部分算法進(jìn)行調(diào)整,進(jìn)而篩選出這些優(yōu)質(zhì)站點(diǎn),推送給用戶。當(dāng)然,在做的過(guò)程中還有更多的參考因素,比如域名年齡、JS數(shù)量,網(wǎng)站速度等。
******************拓展閱讀1結(jié)束***************************************
******************拓展閱讀2開始***************************************
你們說(shuō),為什么當(dāng)站文章中有大量相同時(shí),會(huì)快速引起搜索引擎懲罰呢?這里我說(shuō)的不是摘抄與原創(chuàng)的問題,而是你站內(nèi)自己和自己的文章重復(fù)。之所以搜索引擎反應(yīng)這么快,同時(shí)懲罰嚴(yán)厲,根本原因就是在你的文章中,他提取不到內(nèi)容1。
******************拓展閱讀2結(jié)束***************************************
好,經(jīng)過(guò)這一系列處理,我已經(jīng)獲得了內(nèi)容1與內(nèi)容2了,下面該進(jìn)行原創(chuàng)識(shí)別的算法了。
現(xiàn)在基本上搜索引擎對(duì)于原創(chuàng)的識(shí)別,在大面上采用的是關(guān)鍵詞匹配結(jié)合向量空間模型來(lái)進(jìn)行判斷。Google就是這么做的,在其官方博客有相應(yīng)的文章介紹。這里,我就做個(gè)大白話版本的介紹,爭(zhēng)取做到簡(jiǎn)單易懂。
那么,我通過(guò)分析內(nèi)容1,得到內(nèi)容1中權(quán)重最高的關(guān)鍵詞k,那么按照權(quán)重大小進(jìn)行排序,前N個(gè)權(quán)重最高的關(guān)鍵詞的集合我命名為K,則K={k1,k2,……,kn},則每一個(gè)關(guān)鍵詞都會(huì)對(duì)應(yīng)一個(gè)其在頁(yè)面中獲取到的權(quán)重特征值,我將k1對(duì)應(yīng)的權(quán)重特征值設(shè)定為t1,則前N個(gè)權(quán)重關(guān)鍵詞對(duì)應(yīng)的特征值集合則為T={t1,t2,……,tn},那么我們有了這個(gè)特征項(xiàng),就能計(jì)算出其相對(duì)應(yīng)的特征向量W={w1,w2,……,wn}。接著我將K拼成字符串Z,同時(shí)MD5(Z)則表示字符串Z的MD5散列值。
那么假定我判定的兩個(gè)頁(yè)面分別是i與j。
則我計(jì)算出兩個(gè)公式。
1.當(dāng)MD5(Zi)=MD5(Zj)時(shí),頁(yè)面i與頁(yè)面j完全相同,判斷為轉(zhuǎn)載。
2.設(shè)定一個(gè)特定值α
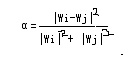
當(dāng)0≤α≤1的時(shí)候,我判定頁(yè)面相似為重復(fù)。
由此,對(duì)于原創(chuàng)文章的判斷就結(jié)束了。好了,苦逼煩悶的枯燥講解告一段落,下面我用大白話再重新復(fù)述一遍。
首先,你的內(nèi)容一模一樣,一個(gè)字都不帶改的,那肯定是摘抄的啊,這時(shí)候MD5散列值就能迅速的判斷出來(lái)。
其次,很多SEO他們懶,進(jìn)行所謂的偽原創(chuàng),你說(shuō)你偽原創(chuàng)時(shí)插入點(diǎn)自己的觀點(diǎn)與資料也成,結(jié)果你們就是改個(gè)近義詞什么的,于是我就用到了特征向量,通過(guò)特征向量的判斷,把你們這些低劣的偽原創(chuàng)抓出來(lái)。關(guān)于這個(gè),判斷思想很簡(jiǎn)單,你權(quán)重最高的前N個(gè)關(guān)鍵詞集合極為相似的時(shí)候,判斷為重復(fù)。這里所謂的相似包括但不僅僅局限于權(quán)重最高的前N個(gè)關(guān)鍵詞重合,于是構(gòu)建了特征向量,當(dāng)對(duì)比的兩個(gè)向量夾角與長(zhǎng)度,當(dāng)夾角與長(zhǎng)度的差異度小于某個(gè)特定值的時(shí)候,我將其定義為相似文章。
********************備注1開始*************
一直關(guān)注google反作弊小組官方博客的朋友們,應(yīng)該看過(guò)google關(guān)于相似文章判斷算法的那篇博文,在那篇文章中,其主要使用的是余弦定理,就是主要計(jì)算夾角。不過(guò)后來(lái)Mr.Zhao又看了好幾篇文獻(xiàn),覺得那篇博文應(yīng)該僅僅是被google拋棄后才解密的,現(xiàn)在大體算法的趨勢(shì),應(yīng)該是計(jì)算夾角與長(zhǎng)度,所以選擇現(xiàn)在給大家看的這個(gè)算法。
********************備注1結(jié)束*************
好的,這里我們注意到了幾個(gè)問題。
1.α被判定為重復(fù)時(shí)的取值范圍是否可變?
2.內(nèi)容中如何提取出關(guān)鍵詞?
3.內(nèi)容中關(guān)鍵詞的權(quán)重值是如何賦予的?
下面我來(lái)逐一解答。
先說(shuō)α判斷重復(fù)時(shí)的取值范圍,這個(gè)范圍是絕對(duì)可變的。隨著SEO行業(yè)的蓬勃發(fā)展,越來(lái)越多人想要投機(jī)取巧,而這是搜索引擎不能接受的。于是就會(huì)隔幾年進(jìn)行一次算法大更新,而且每一次算法大更新,都會(huì)預(yù)告會(huì)影響百分之多少的搜索結(jié)果。那這影響結(jié)果的百分?jǐn)?shù)是如何計(jì)算出來(lái)的?當(dāng)然不是一個(gè)一個(gè)數(shù)的,在內(nèi)容方面(其它方面我會(huì)在其它文章中闡述),是通過(guò)調(diào)整α判斷相似度時(shí)的取值空間變化來(lái)計(jì)算的,每一個(gè)頁(yè)面在被我處理是,我所計(jì)算出的α值都會(huì)存儲(chǔ)在數(shù)據(jù)庫(kù)中,這樣我在每次算法調(diào)整時(shí),風(fēng)險(xiǎn)都可做到最大的控制。
那么如何提取關(guān)鍵詞?這就是分詞技術(shù)了,我待會(huì)再講。頁(yè)面內(nèi)不同關(guān)鍵詞的權(quán)重賦值也在待會(huì)講。
關(guān)于文章相似性,簡(jiǎn)而言之,就是以前大家改一改文章,比如“越來(lái)越多SEO開始重視起文章的質(zhì)量。”改為“高質(zhì)量的文章被更多的SEO所重視”,這個(gè)在以前沒有被識(shí)別出來(lái),不是我沒有識(shí)別你的技術(shù),而是我放寬范圍,我可以隨時(shí)在需要的時(shí)候,通過(guò)設(shè)定參數(shù)的取值范圍,來(lái)重新判斷頁(yè)面價(jià)值。
好,如果這里你有些糊涂,別著急,我接著慢慢的說(shuō)。上述算法里,我需要知道前N個(gè)重要的關(guān)鍵詞以及其所對(duì)應(yīng)的權(quán)重特征值。那這些數(shù)值我如何獲取呢?
首先,要先分詞。針對(duì)于分詞,我先設(shè)定一個(gè)流程,然后采用正向最大匹配、逆向最大匹配、最少切分等方式中的一種來(lái)進(jìn)行分詞。這個(gè)在我會(huì)在我的博文《常見的中文分詞技術(shù)介紹》中講解,在此不再贅述。通過(guò)分詞,我得到了這個(gè)頁(yè)面內(nèi)容1的關(guān)鍵詞集合K。
在識(shí)別內(nèi)容1的時(shí)候,我就已經(jīng)構(gòu)建了標(biāo)簽樹,那么我的內(nèi)容1實(shí)際上已經(jīng)被標(biāo)簽樹拆解為由段落組成的樹狀結(jié)構(gòu)了。
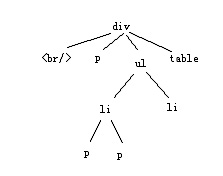
上圖是內(nèi)容1的標(biāo)簽樹。在這里,我遇到一個(gè)問題,那就是針對(duì)標(biāo)簽樹權(quán)重賦值的時(shí)候,應(yīng)該是面向整個(gè)頁(yè)面的標(biāo)簽樹,還是僅僅面向內(nèi)容1的標(biāo)簽樹的?
很多朋友可能會(huì)認(rèn)為,既然是針對(duì)內(nèi)容1的關(guān)鍵詞進(jìn)行賦值判斷,那只處理內(nèi)容1就好了。其實(shí)不然。一款搜索引擎,其處理的數(shù)據(jù)少說(shuō)也要千萬(wàn)級(jí)別的,所以搜索引擎對(duì)于高效率的代碼與算法要求是極高的。
而正常情況下,一個(gè)網(wǎng)站的網(wǎng)頁(yè)是不可能孤立存在的,在對(duì)一個(gè)頁(yè)面針對(duì)某一個(gè)關(guān)鍵詞進(jìn)行排序的時(shí)候,除了要考慮站外因素外,我需要考慮站內(nèi)權(quán)重的繼承,那么在考慮站內(nèi)權(quán)重繼承的時(shí)候,我必然避不開內(nèi)鏈的計(jì)算,同時(shí)內(nèi)鏈本身也應(yīng)該有不同的權(quán)重區(qū)分,而內(nèi)鏈權(quán)重計(jì)算時(shí),我肯定要考慮其所在頁(yè)面與其相關(guān)性。既然如此,我就應(yīng)該一次性對(duì)整個(gè)頁(yè)面所有的信息塊進(jìn)行權(quán)重分配,這樣才是高效率,同時(shí)也充分體現(xiàn)了內(nèi)容與鏈接相關(guān)性的重要性。用一句大家常能在網(wǎng)上看見的話來(lái)說(shuō),就是相關(guān)性決定了鏈接投票的有效性。
好,既然確定下是整個(gè)標(biāo)簽樹進(jìn)行權(quán)重賦值,那么下面開始。
首先,我要確定重要關(guān)鍵詞的詞庫(kù)。重要關(guān)鍵詞的確定通過(guò)兩種方法:
1.不同行業(yè)的重點(diǎn)關(guān)鍵詞。
2.針對(duì)句子結(jié)構(gòu)與詞性的重點(diǎn)關(guān)鍵詞。
每一款較為成熟的商業(yè)搜索引擎,針對(duì)不同行業(yè),其算法都會(huì)有所不同。而行業(yè)的判斷,就是依托于各個(gè)行業(yè)的關(guān)鍵詞庫(kù)進(jìn)行的。最近百度針對(duì)一些特定關(guān)鍵詞,在搜索結(jié)果中返回網(wǎng)站的備案信息和認(rèn)證信息,由此可見,詞庫(kù)其實(shí)早已存在。
那么,句子結(jié)構(gòu)又從何說(shuō)起呢?中文句子不外乎主謂賓定狀補(bǔ)幾個(gè)結(jié)構(gòu)組成,而詞性也僅有名詞、動(dòng)詞、介詞、形容詞、副詞、擬聲詞、代詞、數(shù)詞。相信很多人剛做SEO的時(shí)候,肯定聽說(shuō)過(guò)搜索引擎除噪的時(shí)候,會(huì)去掉的地得和代詞,其實(shí)這種說(shuō)法大面上對(duì),但也并非完全準(zhǔn)確。從根本原理來(lái)說(shuō),是針對(duì)句子結(jié)構(gòu)與詞性而給予處理時(shí)的態(tài)度不同。我們可以肯定,主語(yǔ)一定是最重要的部分,往往一句話主語(yǔ)變了,其針對(duì)的事物和所要表述的意義也就往往不同。而針對(duì)的事物若有變化,極有可能導(dǎo)致這篇文章所涉及的行業(yè)有所變化。故而,主語(yǔ)肯定是我所需要的重點(diǎn)詞。這里為什么我沒有說(shuō)在主語(yǔ)部分去掉代詞呢?因?yàn)橥サ糁髡Z(yǔ)會(huì)使得句子失真,所以我要保留主語(yǔ)所有屬性的詞,即便是看起來(lái)沒有意義代詞。
那么定語(yǔ)呢?往往定語(yǔ)決定了一個(gè)事物的程度或性質(zhì),所以定語(yǔ)也很重要。但問題就來(lái)了,對(duì)于用戶來(lái)說(shuō),美麗的畫與漂亮的畫是同一個(gè)意思,而美麗的畫與難看的畫卻是相反的意思。同時(shí)其它句子結(jié)構(gòu)例如補(bǔ)語(yǔ)作為句子的補(bǔ)充,往往承載了地點(diǎn)、時(shí)間等信息量,那也很重要。若是如此,那我又要如確定我認(rèn)為最主要的關(guān)鍵詞呢?
這個(gè)問題確實(shí)很復(fù)雜,但其實(shí)能夠解決它的辦法既簡(jiǎn)單又困難。那就是時(shí)間與數(shù)據(jù)的積累。也許有人會(huì)覺得我這么說(shuō)是不負(fù)責(zé)任,但事實(shí)卻是如此。倘若這個(gè)世界上沒有SEO、沒有偽原創(chuàng),那么搜索引擎可以高枕無(wú)憂,因?yàn)闆]有偽原創(chuàng)的干擾,搜索引擎可以迅速的識(shí)別出轉(zhuǎn)載內(nèi)容,然后非常輕松的計(jì)算排名。但有了偽原創(chuàng)之后,其實(shí)每一次內(nèi)容判斷算法的調(diào)整,更多的是對(duì)目前一些常見的偽原創(chuàng)做法進(jìn)行識(shí)別。正因?yàn)橛袀卧瓌?chuàng)的存在,如果是我設(shè)計(jì)策略,我會(huì)設(shè)計(jì)出兩個(gè)詞庫(kù),詞庫(kù)A是用于區(qū)分內(nèi)容所從屬的行業(yè),詞庫(kù)B則是針對(duì)不同行業(yè),然后在設(shè)置若干規(guī)則與這兩個(gè)子詞庫(kù)進(jìn)行關(guān)聯(lián)。
舉例。比如偽原創(chuàng)猖獗的醫(yī)療SEO,通過(guò)一些病種詞,可以迅速識(shí)別出其內(nèi)容屬于醫(yī)療行業(yè)。那么在選擇的時(shí)候,鑒于某些原因,我將嚴(yán)厲對(duì)待醫(yī)療,則我認(rèn)為醫(yī)療文章內(nèi)容重要的僅僅是充當(dāng)主語(yǔ)的名詞,然后在充當(dāng)主語(yǔ)的名詞中,病種名詞作為最優(yōu)先,進(jìn)而進(jìn)行優(yōu)先級(jí)排序,在排序中若主語(yǔ)名詞數(shù)大于N,則按照其所處的信息塊距離根節(jié)點(diǎn)最近最有先原則,并且同一名詞僅選擇一次,然后選取前N個(gè)重要關(guān)鍵詞作為賦值的初始節(jié)點(diǎn),進(jìn)行權(quán)重賦值。
那么在賦值的時(shí)候,我設(shè)定賦值系數(shù)e,我可以判斷在這幾個(gè)被賦值的節(jié)點(diǎn)上,根據(jù)關(guān)鍵詞種類來(lái)確定賦值的比重。比如與title中重復(fù)的病種名詞,其對(duì)應(yīng)的系數(shù)為e1,與title中不對(duì)應(yīng)的病種名詞系數(shù)為e2,其它名詞系數(shù)為e3。然后我開始遍歷標(biāo)簽樹。
整個(gè)頁(yè)面自身權(quán)重為Q,按照前N個(gè)關(guān)鍵詞的順序依次遍歷。那么我的遍歷原則如下:
1.第一次遍歷時(shí),第一個(gè)重要節(jié)點(diǎn)權(quán)重值為Qe1,其父節(jié)點(diǎn)權(quán)重值為Qe1*b,其子節(jié)點(diǎn)權(quán)重值為Qe1*c,然后以此原則繼續(xù)遍歷父節(jié)點(diǎn)的父節(jié)點(diǎn)及其父節(jié)點(diǎn)的子節(jié)點(diǎn)和子節(jié)點(diǎn)的子節(jié)點(diǎn)及其子節(jié)點(diǎn)的父節(jié)點(diǎn)。
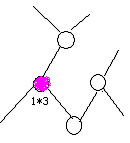
以下舉例。假定Q為1,e1為3
則一開始如下圖
然后假定a為上一個(gè)數(shù)的平方根,b為上一個(gè)數(shù)的立方根。則如下圖
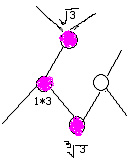
接著開始遍歷其它節(jié)點(diǎn)。

當(dāng)整個(gè)網(wǎng)頁(yè)標(biāo)簽樹的所有節(jié)點(diǎn)全部被賦值后,第一次遍歷結(jié)束。這時(shí)候開始第二次遍歷,注意這時(shí)候與e2相乘的就不是Q了,而是第二個(gè)重要關(guān)鍵詞所在節(jié)點(diǎn)的當(dāng)前權(quán)重值。
這樣經(jīng)過(guò)N此遍歷,每一個(gè)信息塊都會(huì)有自己相對(duì)應(yīng)的權(quán)重?cái)?shù)值,然后我單獨(dú)提取內(nèi)容1的信息塊,具體上文中有畫圖,在此就不再多畫了。將內(nèi)容1量化。量化后,我就能夠得到上文中我所需要的權(quán)重特征值T={t1,t2,……,tn}。由此,這個(gè)算法層就首位相應(yīng)的完善了。量化公式很多,我在此就不舉例了,因?yàn)檫@個(gè)舉例毫無(wú)意義,我又不是真寫搜索引擎。
*******拓展閱讀3開始************************************
鏈接模塊的權(quán)重,將最后被超鏈接傳到至其所指向的頁(yè)面中。這也說(shuō)明了不同位置的鏈接,其傳導(dǎo)的權(quán)重各不相同。內(nèi)鏈的位置決定了內(nèi)鏈的權(quán)重繼承。而大家經(jīng)常聽到的,內(nèi)鏈上下文要出現(xiàn)關(guān)鍵字,其實(shí)就是這個(gè)算法所衍生出的現(xiàn)象。
*******拓展閱讀3結(jié)束************************************
至此,這個(gè)算法層基本結(jié)束了。
******聲明1開始*****************************************
1.我再次強(qiáng)調(diào),文中算法不是我寫的,是我借鑒別人的,借鑒誰(shuí)的?我忘了……,好多好多。
2.所有有經(jīng)驗(yàn)的商業(yè)搜索引擎,其算法肯定是分層的,絕對(duì)不會(huì)僅僅是一個(gè)算法層,所以這個(gè)單一的算法層,對(duì)排名來(lái)說(shuō)可以說(shuō)影響很大,但絕對(duì)不是完全按照這一個(gè)算法層來(lái)進(jìn)行排名的。
3.本文首發(fā)Mr.Zhao的SEO博客,轉(zhuǎn)載請(qǐng)保留原文出處:http://www.seozhao.com/379.html
******聲明1結(jié)束*****************************************
那么大致了解了這一個(gè)層的算法之后,對(duì)我們的實(shí)際操作有什么具體的幫助嗎?
1.我們可以有效知道,如何合理的設(shè)置內(nèi)容頁(yè)的欄目布局,使得我們?cè)谵D(zhuǎn)載文章時(shí),讓百度知道我們?cè)谵D(zhuǎn)載文章的同時(shí),為了更好的用戶體驗(yàn)而聚合了各方觀點(diǎn)的文章。
2.我們可以更好的知道,哪些文章會(huì)被判定為相似文章。
3.這個(gè)是最重要的一點(diǎn),就是我們能夠更好的對(duì)內(nèi)容頁(yè)面進(jìn)行布局。真正的白帽SEO,在對(duì)站內(nèi)進(jìn)行梳理時(shí),其站內(nèi)欄目在頁(yè)面上的布局尤為重要,有經(jīng)驗(yàn)的SEO能夠有效的利用頁(yè)面的權(quán)重繼承,進(jìn)而增加長(zhǎng)尾排名,這對(duì)于門戶網(wǎng)站或是B2C等擁有大量?jī)?nèi)容頁(yè)的網(wǎng)站來(lái)說(shuō),非常重要。當(dāng)然,在長(zhǎng)尾排名方面,對(duì)頁(yè)面權(quán)重傳輸?shù)牧私馀c布局僅僅是基礎(chǔ),今后我會(huì)在后續(xù)文章中,在對(duì)欄目層級(jí)設(shè)置與權(quán)重傳遞方面,針對(duì)我的觀點(diǎn)進(jìn)行闡述。
4.明白內(nèi)鏈權(quán)重繼承的大致原理。
來(lái)源:Mr.Zhao投稿,原文鏈接。
該文章在 2025/2/24 15:43:48 編輯過(guò)


 400 186 1886
400 186 1886
晴公司官網(wǎng)")


晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")